
What kind of index would be efficient for searching big data?
I think this is one of the most interesting project that I have worked on. In this project, I will have to deal with a very large text file (more than 1 GB) with lots of actors, actresses names and movie names that those movie star cast in,(data is from IMDB). My goal is to figure out the most efficient way to do the search, the less time spend the more it it efficiency.
In my approach, I build a basic hash index in dictionary structure in Python to increase the searching efficient of this big data. Because the normal search needs to take 1 second for exactly 1 character, which is too slow, in my approach, I successfully decrease the searching time less than 0.5 second.
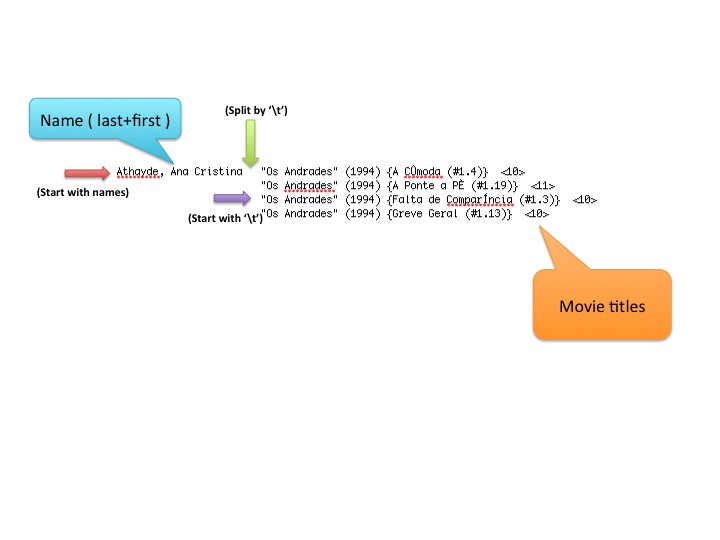
raw data format
As you can see the raw data format I got is actors’ name with movie he cast seperate with a single tab, thus, first step of all is to re-format the data in order to use it.
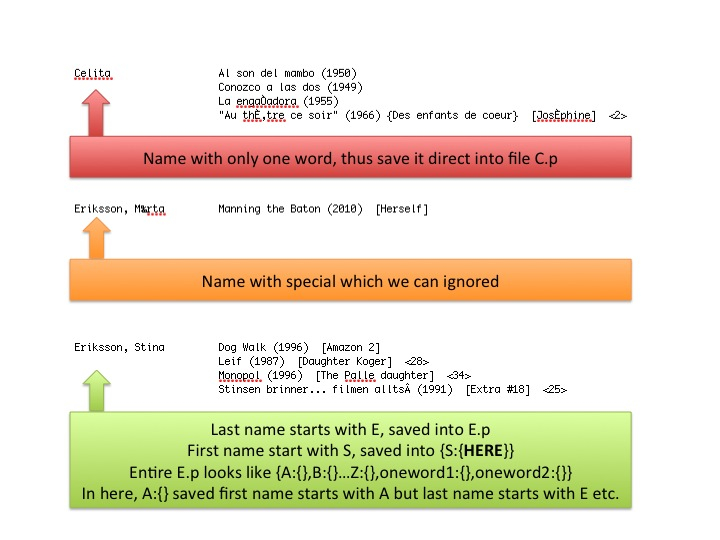
Hash structrue
The key element to speed up the searching is the data structure. I used hash which is key-value lookup table, the key is the first letter of last name, start from A to Z, and then it is associated with another hash its key is based on the first letter of first name.
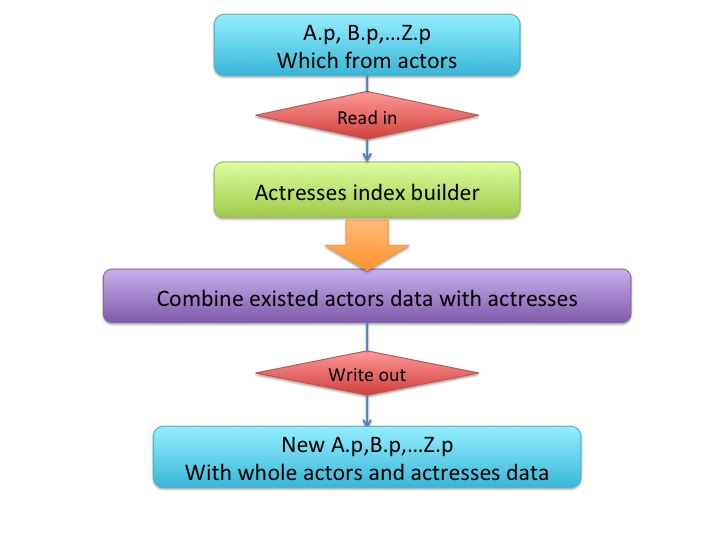
Index Builder
Index builder is the key element of entire program, it loaded the raw data, re-format and save it into memory in order to do search.
This is the basic workflow of entire program:
- use index builder to re-format actors’ data
- use index builder to re-format actresses’ data
- combine and output result 1 & 2
Demo
- Initialization of entire program, loading and re-formatting data from A to Z alphabetically.
- Type search query to search
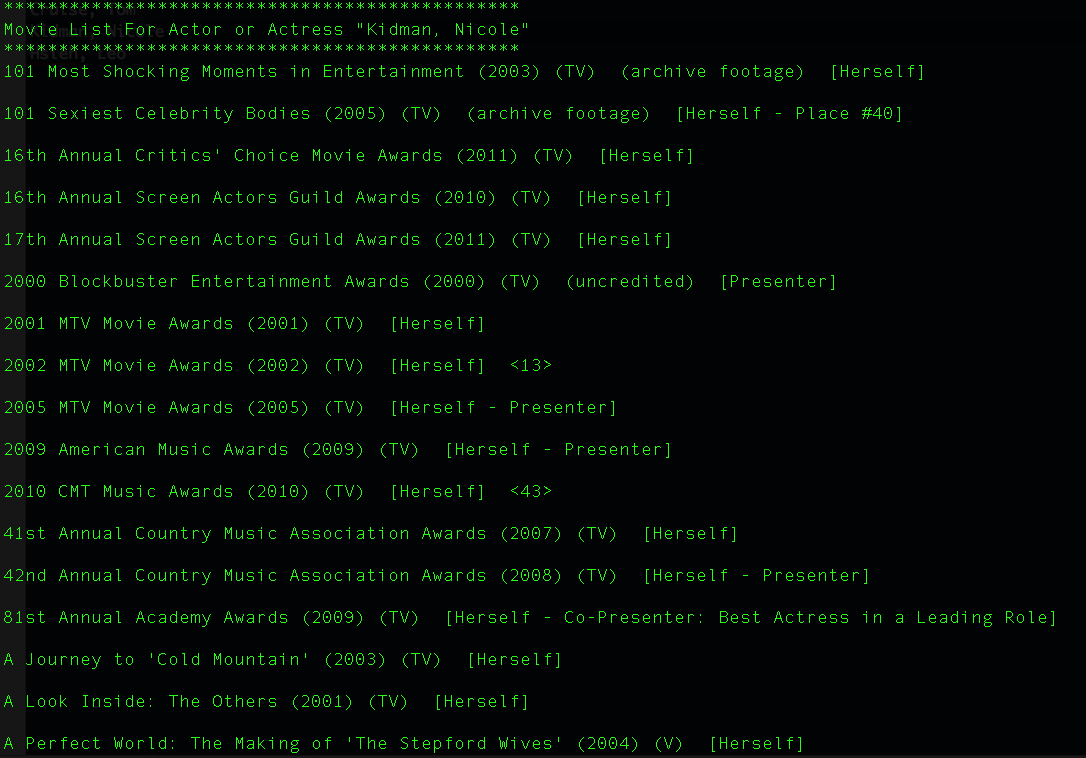
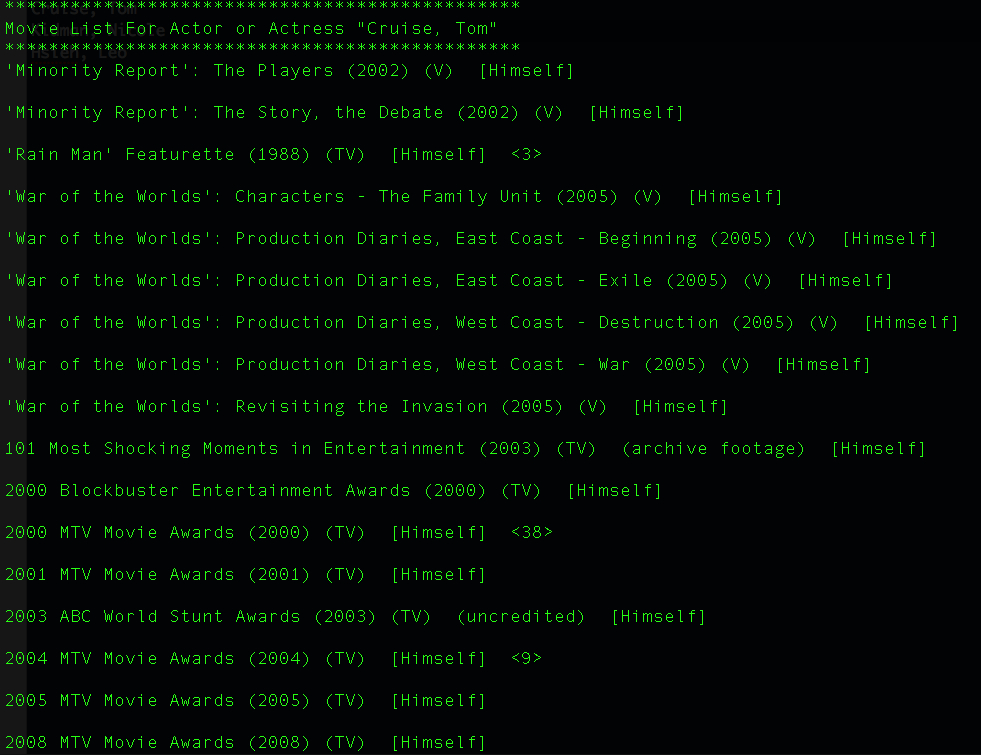
Conclusion
Right now I think it is very obvious that the picture on the top is the search result of my name, of cource that I am not movie star. How to effcient use data is always huge challenges, and I am enjoy of solving those challenges.
Python,Big Data